Developer-Led Landscape: Cloud Native Application Development
Over 200 Cloud Native Development Companies Representing $100B in Market Capitalization

Designing and building cloud native applications is hard.
Products and companies that help developers design cloud native applications are some of the most sought after by enterprises, venture capitalists, and major vendors.
Let’s discuss the underlying trends, why building stateful and resilient systems is hard, and segment startups by their varying approaches.
Cloud Native Development Startups Have Attracted $2.85 Billion in Venture Capital
Scaling a stateful system is big business. There are over 200 companies which have raised $2.85B in venture capital. When combined with the products that are also offered by hyperscalers and platform vendors, these firms collectively represent $27B in annual revenues with market value approaching $100B.

Cloud Native Development Is Part of the Developer-Led Landscape
This article is a continuation of the Developer-Led Landscape, published in September 2020.
Why Is Building a Cloud Native Application Hard?
Building a cloud native, edge native, or Internet of Things (IoT) application means developing and running a distributed system on unreliable hardware across unreliable networks.
These problems must be addressed at both the compute and application layer. Applications, authored by software developers, address these issues with abstractions, programming models, protocols, interaction schemes, and error handling.
Infrastructure Solutions Are Necessary but Not Sufficient
Lately, it’s become in vogue to treat these issues as an afterthought, delegated as an operational or infrastructure problems to be delegated to an underlying infrastructure stack, which unfortunately usually has a leaky abstraction.
One concern is that depending on infrastructure like Kubernetes to solve these problems eventually breaks down if you want to build applications in areas where that infrastructure may not be, such as on endpoint devices or the edge.
Scaling Application State Is Hard — Devs Must Address Single Points of Failure and Consistency
Cloud environments excel at scaling stateless services but challenges occur with stateful applications because database calls to fetch state are slow. Having every state request trombone to a database outside of the application creates a trombone effect that impacts round-trip times (RTT), which individually aren’t a massive impact, but collectively are significant.
Additionally, a database is usually a single point of failure. If the database is not available, all services depending on it are blocked. If your application has multiple services (it does) then synchronous service-to-service calls can lead to cascading failures if any single service depends upon a database — even if that database is replicated and distributed!
A resilient system must be flexible by embracing the network. Its nodes will live in multiple locations simultaneously so that the system can continue to function when underlying hardware is inaccessible. This form of spatial decoupling, where nodes have state outside of the database, requires the application developer to incorporate consistency to allow the system to work towards convergence where different nodes can (eventually) make identical conclusions. Strong consistency, offered by a system with a database as the single point of failure is an ideal, but again not scalable. Cloud native systems must design for eventual consistency or causal consistency, both of which tolerate delays and temporary unavailability of participants.
Cloud Native Application Development Is on the Rise
According to Gartner, IDC, and Goldman Sachs, containers are shaping into a $7 billion opportunity by 2021. 75% will be for deploying new applications enabled by containers, especially cloud native apps.
App modernization from cloud native applications will be the largest Kubernetes workload.
A cloud native application takes advantage of the underlying platform’s ability to optimize resource consumption, scale dynamically, and recover quickly if any portion of the system goes down.
IDC further indicates that adopting a microservices paradigm is essential to building cloud native applications, as the componentized architecture enables maximum leverage of an underlying platform’s optimization, scale, and resilience functions. IDC further concluded that by 2021, 45% of applications will be built using a microservices architecture.
Approaches for Designing and Developing Cloud Native Applications
There are numerous mechanisms for delivering scalable stateful applications that minimize, avoid, or eliminate the database as the scaling bottleneck.
The following four sections offer different approaches to how state can be scaled successfully.
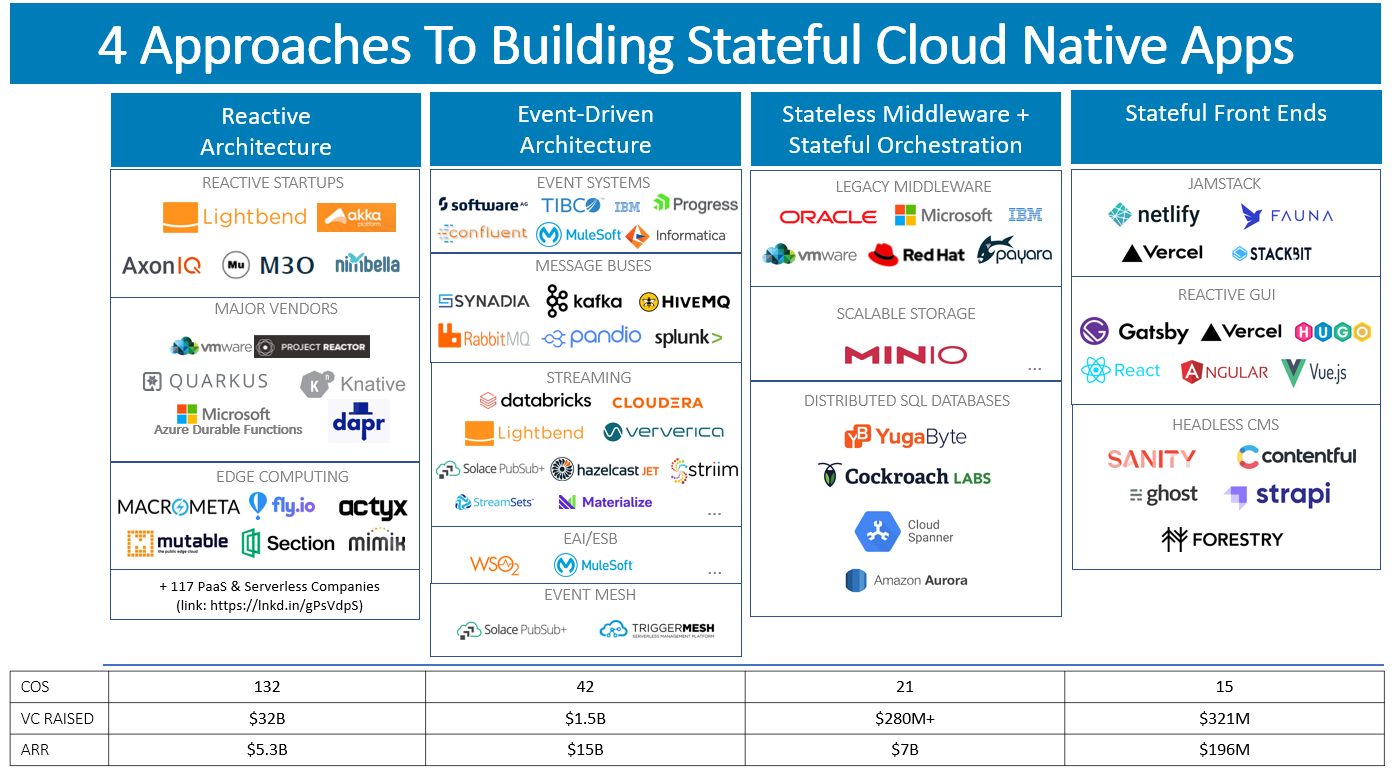
Approach 1: Reactive Architecture for Stateful Microservices and Stateful Serverless
Reactive systems are designed to simultaneously be responsive (always responds in a timely manner), resilient (stays responsive in the face of failure), elastic (stays responsive under varying workload), and message-driven (asynchronous message passing between boundaries).
Reactive cloud native applications avoid stateful scaling problems:
Speed. Each service manages its own state in memory. Services communicate directly with each other asynchronously. The database is accessed asynchronously for event sourcing / event logging.
Resilience. Services automatically rebalance state and self-heal in cases of failure.
Scale. Services automatically scale up to handle peak workloads and scale down when not needed.
Through thoughtful design and the right selection of eventing and microservices technology, any application can be a reactive application.
Technologies for Building Reactive Systems Span the Range of Advanced Computer Science and Distributed Systems
Reactive systems embrace logical clocks, vector clocks, CRDTs, actor model, domain-driven design, event sourcing, CQRS, event-driven architecture, finite state machines, futures/promises, dataflow variables, async/await, and coroutines.
Adrian Colyer’s blog is essential reading for staying on top of the latest advancements in these technologies.
The Reactive Principles: An Industry-Wide Collaboration of Distributed Systems Experts To Define Practices and Patterns Which Make an Application Reactive and Cloud Native
In Q3 2020, a group of experienced application development design and implementation practitioners came together to outline eight principles of design in The Reactive Principles. The principles incorporate ideas, paradigms, methods and patterns into a practical set of guidelines for architecture. The principles are vendor neutral, allowing for different middleware systems to embrace their ideals with different implementations, and a follow-on from the Reactive Manifesto, a precursor document that has 29,000 signatories.
Reactive Architecture Startups Have Raised $70M in VC, Powering Many of the World’s Largest Applications, and With 100s of Millions of Monthly Downloads
Lightbend Akka, which is the widest adopted technology with nearly 70 million monthly downloads and robust list of reference implementations. Lightbend has also donated Cloudstate to the Reactive Foundation, an open source project that provides a standard approach to using any programming language to build stateful serverless apps. (I’m also a supportive investor!)
AxonIQ (taking a more literal interpretation of how CQRS and event sourcing should be handled).
Micro Inc. (a set of Go components that individually offer reactive services similar to Microsoft DAPR).
Nimbella (provides a declarative approach based upon Apache OpenWhisk to separating state from logic).
Reactive Architecture Products From Major Vendors
Major vendors have a number of efforts underway to package reactive architecture for their existing developer communities. This includes:
VMware Project Reactor (for building non-blocking application on the JVM).
RedHat Quarkus (subatomic Java stack that unifies imperative and reactive styles).
Google KNative (platform of building blocks for running stateful serverless workloads on Kubernetes).
Microsoft DAPR (portable runtime with stateful serverless building blocks).
Microsoft Azure Durable Functions (based on DAPR).
117 PaaS and Serverless Companies Generating $5.2B in Revenues Demonstrate Reactive Architecture Operating At Scale
In the latest version of the Developer-Led Landscape, there are 117 companies with $5.2B in revenues that have a Platform as a Service (PaaS) offering, many of which specialize in scaling applications or promote a serverless architecture. And many serverless products implement reactive architecture under the covers.
These products address stateful concerns in a few ways:
They don’t, making them only suitable for stateless activities.
They force an app developer to delegate state to an underlying database.
They abstract state, usually by creating a proprietary interface that a developer must code against, which allows their platform to manage the stage for the developer through replication and varying consistency guarantees. Under their abstraction is that vendor’s implementation of a reactive architecture.
Local-First Development Extends Reactive Concepts to the Edge … Attracting Over $100M in VC Investment, the Beginning of Standards Activity, and Limited Adoption
As computing power within handheld and IoT devices increase, and 5G creates the potential for 1000x more data centers located within miles of one another, the potential for applications to run “locally - either on a device or in a local data center” increase.
Applications “on the edge” can have local interaction to mitigate the extra latency and risk of interaction via a central exchange, make decisions in collaboration with other nearby applications, alter behavior based upon the nature of local clients, and expect dynamic changes from the network neighborhood.
Edge applications must embrace an architecture that enables the best parts of Reactive Architecture, but further extend it to accept that a) data consistency patterns vary by locale, b) local computing devices may take actions different from central systems, c) state may have multiple dimensions, flowing east-west to different locales and north-south between locales and the cloud.
Early thought leaders have written about local-first software, and industry experts including a number of startups are now participating in local-first principles. The European Union sponsored a three-year study to develop an edge reference architecture.
Over $100M in VC has been raised by edge architecture startups including Macrometa, Modokura, Mutable, Section, Fly.io, Actyx, and Mimik. None of these companies have had extensive adoption or broken above $10M in revenues, probably due to limited demand for application developers to build cloud native apps that are local-aware. I believe we need sub 5ms 5G to arrive before developers increasingly design systems that will be edge-first.
Approach 2: Event-Driven Architecture (EDA) and Event Streaming for Loosely-Coupled State Processing
EDA is a software architecture paradigm that promotes the production and reaction to events, which is a significant change in state. EDA systems consists of event emitters, event consumers, and event channels. Message-oriented middleware systems provide horizontal scalability and delivery guarantees for systems whose production and consumption of messages must be loosely-coupled across distributed emitters and consumers.
A key principle of Reactive Architecture is that they are message-driven, and from that perspective, EDA is either a stand alone architecture for designing stateful systems or a building block that combines with CQRS and event sourcing to deliver resilient and elastic behaviors.
While EDA has been popularized as great for building cloud-native systems, having systems communicate through asynchronous messages is a necessary, but not sufficient condition for becoming cloud native. EDA cannot gaurantee responsiveness, accept uncertainty, tailor consistency, or assert autonomy while having an application hold its state in memory, or near-memory.
Events Are Foundational To Developer-Driven Landscape: 42 Companies Generating $8.2B in Revenues, Having Raised $1.5B in Venture Capital
Messaging products have been around for 50 years.
Software AG, Tibco, and IBM had significant growth in their software divisions driven by messaging products. Prior to BEA acquiring Weblogic and becoming the Java company, it had acquired Tuxedo in the early 90s, a C-based messaging system that was over $200M in revenues. Fun fact, your author had a college engineering internship at a company in the 90s that was eventually acquired by Tibco and got to design and (partially) implement a negative ACK-based guaranteed message delivery system.
With $8.2B in revenues, event systems are not only the foundation for Reactive Architecture, they are also the nervous system running most of the cloud systems on the planet. They represent 20% of the revenues across the developer-led landscape.
Events Are the Strategic Nervous System of Cloud Native Applications and Reactive Architecture Generating Nearly $50B in Market Capitalization
It’s this strategic nature of eventing which has made many companies that get global adoption of their messaging architectures into super unicorns - including Confluent @ $4.5B, Mulesoft @ $6.5B, along with the significant market caps of Tibco, Informatica, Progress Software, and Software AG. Collectively, the large scale messaging vendors have market capitalizations over $50B.
Message buses take different forms and flavors, providing a range of different semantics for how messages can be sent / received, the relative guarantees the bus provides on message delivery and ordering, multi-tenancy, message sharing, authentication, high availability, and observability.
Message Buses Gain Significant Adoption Through Long-Lived (>10 Year) Open Source Incubation
NATS: A high-throughput, distributed messaging bus that originated as part of Cloud Foundry and ideal for edge, local-first, and embedded messaging scenarios. Commercialized by Synadia, which has raised $6M in a seed round.
Kafka: Originally conceived as an append-only log for storing logs, the architecture proved ideal for high scale messaging where every message must be persisted and potentially delivered with an ordering guarantee. Unlike NATS, Kafka’s delivery guarantees require a more complex architecture which creates overhead and higher cost of operation. Popularized at LinkedIn, it’s often seen as a core infrastructure within a cloud native environment. It’s commercialized by Confluent, Instaclustr, the hyperscalers, and a number of smaller startups offering managed variants.
MQTT: A messaging standard ideal for IoT scenarios. It’s lightweight, efficient, bi-directional communication (ie, the server can initiate communications with a device), and designed for working in unreliable networks. MQTT clients are embedded in many IoT devices and a number of MQTT brokers have emerged to reliably and scalably bridge event flows between devices and a central cloud. HiveMQ is the leading startup with numerous implementations in industrial and automotive environments. A number of classic messaging brokers have added MQTT extensions for interoperability including IBM, Microsoft, and Solace.
Classic Message-Oriented Middleware: Spanning a range of popular technologies that (mostly) have open source communities thriving for over 10 years, this includes Apache Pulsar (commercialized by StreamNative, Pandio and Splunk), RabbitMQ (commercialized by VMware), IBM MQ, Oracle Tuxedo and Weblogic Messaging, Tibco Rendezvous, Software AG Universal Messaging, Progress SonicMQ, Solace PubSub+ Platform, Alachisoft NCache, and many more.
Cloud Queues: Whether provided by a hyperscaler or a cloud startup, a purely managed offering with self-service developer send / receive of events are systems that hide the complexity of operating a messaging network, while also allowing the cloud provider to create their own simplifying abstractions over queues, topics, events, and how clients who send and receive messages are authored. Leading providers include AWS Simple Queue Service, AWS Simple Notification Service, Azure Functions and Queue Storage, Tencent Cloud Message Queue, and Google Firebase Cloud Messaging.
Event Streaming Adds Continuous Processing to Capture Value From Data-in-Motion With Startups Grabbing Nearly $1B in Venture Capital
If an event is data packaged as a message, then a stream is a continual flow of events. Stream processing is the evolution of EDA to apply time-bound and continuous processing of events. This segment of the market was originally conceived as Complex Event Processing at the turn of the millennium, but I suppose calling it streaming makes this market segment feel more like Netflix than PBS.
Most of the classic messaging vendors have added streaming capabilities to varying levels of success. Other companies, with a streaming-first orientation have collected over $1B in venture capital approaching $10B in market capitalization. Best guess is that we are approaching $750M in annualized spend on streaming offerings with growth between 25% and 40%.
This includes:
Open Source Variants: Apache Spark (commercialized by Lightbend, Databricks, and Cloudera), Apache Storm, Apache Heron, Apache Nifi (commercialized by BatchIQ and Cloudera), Apache Kafka Streams, Apache Samza, Apache Flink (commercialized by Ververica), and Apache Beam (commercialized by Cloudera). Although a bit dated, this article provides a breakdown on how each specializes.
Platform Vendor Streaming Solutions: Google Cloud Dataflow, Amazon Kinesis Data Streams, Microsoft Azure Event Hubs, IBM Event Streams, SAS Event Stream Processing, VMware Spring Cloud Data Flow, Red Hat AMQ Streams.
VC-Backed Startup Products: Lightbend Akka Data Pipelines, Hazelcast Jet, Solace PubSub+, StreamSets, Striim, and Materialize.io.
Enterprise Application Integration (EAI) and Enterprise Service Buses (ESBs) Leverage EDA To Integrate Integration Legacy Generating $50B in Market Capitalization
Starting at the turn of the century, ESBs became the standard for how organizations would integrate legacy systems to speak to one another. Built upon messaging buses and part of the EDA category, ESBs add last mile adapters to applications, provide developer tools for orchestrating workflows between different applications, and address complex transformation issues as messages flow between different environments.
ESBs and EAI are typically deployed as part of a center of excellence, and many large organizations have people identified as Integration Architects responsible for organizing how a variety of constantly changing systems will interact.
In the Developer-Led Landscape, these legacy products span 22 companies generating $6B in revenues. Never sexy, but almost always essential, the underlying infrastructure that binds different applications and data together as part of an integration backbone are so valuable that the collective market valuation applied to these products is over $50B.
While the market is drawn to the $6.5B acquisition of Mulesoft by Salesforce, I personally think the more impressive company is WSO2, which is the largest open source integrator with over 650 employees globally.
Event Bridges & Hubs Emerging as a New Class of “Event Mesh” Across Hyperscalers, Standards, and Startups to Bridge Event Triggers with Event Sources for Multicloud Applications
The serverless style of event-driven applications is simple - an event triggers a function to run on demand. This works well when the event sources that an application requires are generated from a homogeneous system. But what if the event sources span many different systems, clouds and applications?
Event bridges are an emerging type of EDA solutions that provide a type of Multicloud Event Bus, standardizing the flow of event triggers, their format, and an ability to execute consumers that reside in different locations. They can even link on-premise message buses with cloud-based systems.
Some early work is being done by Triggermesh (raised $3M in venture capital in a seed round in 2020), Solace PubSub+ Event Broker (a mid-sized company that experienced a leveraged buy out in 2016 and effectively re-positioned as a cross-environment event mesh), and the Serverless Event Gateway (an orphaned project from the makers of the Serverless Framework).
Some early standards work has been sponsored by the CNCF with CloudEvents (a CNCF Serverless Working Group specification for describing event data).
Approach 3: Stateless Middleware Running On Stateful Orchestration (Horizontally Scalable Storage + Planet-Scale Database)
Classic middleware promotes an architectural paradigm where logic modules are statelessly packaged with standard API interfaces that execute request-reply dynamics with calls to underlying databases. The underlying storage system and database continue to act as scaling bottlenecks.
Legacy Middleware Structures How Mobile, Web and Business Apps Are Horizontally Scaled
The products are too many to list, but are some of the widest deployed frameworks used by developers over the past two decades. This includes Microsoft .NET, Oracle Weblogic, IBM Websphere, VMware Spring Framework, Red Hat Wildfly JBoss, Payara Server (along with a number of other vendors) supporting the JakartaEE + Eclipse MicroProfile standards (the evolution of what came from Sun Microsystems’ JavaEE standards).
These products represent an additional $5.7B in annual revenues companies.
Horizontally Scaled Storage for Kubernetes With Distributed SQL Databases Enable Leverage of Stateless Services and Legacy Middleware
If an application can get access to any data that it needs regardless of where that application is running, then a system built with stateless services can be scaled horizontally.
Strategies For Managing Persistent Data
In order to do this, however, the underlying storage mechanism would need to be highly available, hybrid-cloud ready, high performance, enable data replication and backup, secure data, and provide consistent performance at any scale.
A number of technologies are coming to market which make hybrid and multi-cloud systems easily scale their storage. We’ve also seen the evolution of storage types, offering Web-scale object and file storage with restful access.
We are particularly excited and impressed the significant growth seen by one of our investments, Minio, which is approaching 1 billion downloads of their open source, S3-like object storage system. Additional companies focusing on software defined storage for scaling applications include StorageOS (raised $11M in venture capital), Robin Systems (raised $39M in venture capital), and Quobyte (raised $7M in venture capital). Additionally, Portworx was acquired by Pure Storage for $375M to expand their flash portfolio. And Rancher Labs, acquired by Suse in 2020, added commercial support for Longhorn, a CNCF sandbox project for container-based persistent storage.
Additionally, the infrastructure orchestrator on top of the storage system must be volume-aware, in order to map the various services running within the orchestration to gain access to the correct underlying volume.
Once the orchestrator is volume-aware, the operations team can implement a variety of persistence techniques, storing data using host-based persistence (data residing in the hard drive of the host machine running an application’s process), explicit shared storage (mapping to a data volume to share data across application processes), shared multi-host storage (shared, distributed, and replicated file systems such as Ceph, GlusterFS, and Network File System).
Will Distributed SQL Databases Eliminate Single Point of Failure Issues?
Finally, a number of distributed SQL databases are starting to emerge, either through innovative startups or as part of hyperscalers. These technologies allows developers to interact with a database through standard SQL interfaces, but the underlying database engine handles replication of data so that writes are nearly instant and reads are even faster. The nodes of these databases can be deployed across regions and clouds to enable a variety of replication modes to give a balance between performance and availability.
The leaders:
Yugabyte: Started by the team that built Cassandra at Facebook, Yugabyte leverages PostgreSQL to create a massive scale, global database with single-digit millisecond latency, millions of transactions per second, and geo-distribution. Yugabyte is open source and received $54M in venture capital funding from Dell Technologies Capital, Lightspeed Venture Partners, Wipro Ventures, and 8VC.
Cockroach Labs: An earlier entrant into the distributed SQL space that competes on similar dimension as Yugabyte, has raised nearly $200M in venture capital from a range of investors which include Google Ventures, Sequoia Capital, Index Ventures, and Redpoint. There is a WWE-level technical smack down happening between two heavyweights as they demonstrate their scale in technical arguments here, and with counter arguments here and here. The winner is the community with gaining access to more forms to build SQL-based systems that reduce (but not entirely eliminate) the single point of failure issue.
Google Spanner and Amazon Aurora: Hyperscaler databases that provide SQL abstractions. Generally, easy to get started, but neither are designed for multi-cloud or open source adoption.
Even with planet-scale databases, while you can scale up clusters to increase writes, these systems must eventually deal with contention. That contention can be minimized, but it’s localized to within the storage tier. This is a contrarian approach to what Actors and Reactive Architecture promote, which is that the application is working to eventually achieve consistency, because all of the services are able to operate independently by emitting facts, allowing each autonomous service to be responsive as it operates in the fluid environment.
Will Distributed SQL Databases Eliminate Single Point of Failure Issues?
Finally, applications gain a further boost of performance by replicating sets of data from the underlying persistence layer, whether storage or the database, to be closer to the application in memory with a cache. While cache’s do not resolve issues around consistency and how applications should be designed for autonomous operation and resilience, they do increase responsiveness.
Redis Labs, with over $246M in venture capital raised, is a recent 2020 unicorn, and widely deployed as a caching layer working in cooperation with other storage and database systems. It’s another Dell Technologies Capital investment, and has become the increasingly preferred over memcached or Apache Ignite.
Additionally, Hazelcast, which has raised a significant $66M of its own, provides an application-optimzed caching solution, which had its early adoption from OEMs with its easy-to-embed capabilities leveraged by software developers.
Approach 4: Jamstack, Reactive GUIs, and Headless CMS for Decoupling State, Model and Representation to Scale Stateful Front Ends
While the techniques for scaling a front-end is different than the techniques for scaling a back-end system, there is increasingly a large number of systems which are front-end heavy that bypass the back end direct to a data store.
Front-end applications also need to scale their own state in a number of ways. The content may be replicated across different channels (Web, mobile, or API), it may be have a portion of the content replicated across the application and a separate caching layer such as a CDN, or it may be replicated across the back-end and front-end.
Front-end architectures have emerged to simplify how front-end applications are designed to scale this state while also providing a responsive experience that feels near instant.
Reactive GUIs for Decoupling State, Model and Representation Across Browsers and Mobile Devices Have 100s of Millions of Downloads and Early Venture Capital
This includes Gatsby, Vercel Nextjs, Hugo, React, Angular, and Vue. A big part of the industry is rallying around static site generation, which renders cacheable variations of a Web site when core content or dynamic functions have change. There are numerous open source projects, each of which often have tens of thousands of GitHub stars and millions of downloads.
Jamstack For Fast and Secure Sites With GraphQL Access to Data Have Raised Nearly $200M in Venture Capital and Approaching $100M ARR
This includes Netlify, Fauna, Vercel, and Stackbit.
These companies represent ways for content generators to increasingly focus on what they are good at - content. And then to incorporate their content changes into a developer-style workflow that automates testing, deployment, content distribution, caching, and site scaling. When the lifecycle of front-end content development is designed around a system that is optimized for scaling front-end content, there is a sweet spot of productivity and ease of operations that is met.
Headless CMS for Cross-Channel Content Separates Development, Content Generators, and Site Hosters In Developer-Friendly Ways Raising $54M in Venture Capital with Nearly $30M in ARR.
This includes Sanity, Contentful, Ghost, Strapi, and Forestry.
Dell Technologies Capital: Enterprise Infrastructure Venture Capital for Cloud Native Development
At DTC, we will invest roughly $150M / year in startups at any stage that are defining the next generation of how data centers will be built or operated, how applications will be designed, developed, and managed, and how systems and data will be analyzed or secured.
We have a broad portfolio of investments spanning silicon, networking, storage, data, analytics, machine learning, cyber security, and DevOps.
We have numerous investments mentioned in this summary including Lightbend (the development platform for cloud native applications), Striim (continuous real-time data integration with intelligence), Fly.io (accelerate application state by deploying apps close to users), Minio (high performance object storage), Redis Labs (in-memory cache), and Yugabyte (planet-scale, distributed SQL database).
Vendor Fragmentation, Standards, and A Need For Leadership
This is the first time in 50 years where an infrastructure paradigm shift occurred before the programming paradigm shift.
As is typically the norm, a new workload would emerge, and the developer community would organize around a set of regarding principles around how those workloads should be effectively designed, deployed, and operated. Developers would start slowly, but as their numbers grew, the volume of applications built in the new workload style increased. Vendors would then design orchestration and compute systems optimized for this new style of workload, attempting to create an offering that offered a compelling economic and operational model for the new workload hotness. Vendors were generally competitive, and fragmentation made an infrastructure standard elusive.
This happened across the PC, client-server, object-request broker (CORBA), JavaEE / .NET / 3-Tier, Web Services (WSDL, SOAP, etc.), SOA, and API-first programming paradigms. In each, along with the programming philosophy, vendors would send their brightest technical talent to work with industry consortiums and standards bodies to create common protocols, development data structures, and software packaging constructs.
These “standards” would allow the industry to promote a common direction but allow vendors to compete on different implementations. Developers would gain confidence that by sticking to the standard, their applications would gain some level of future proof from changes and flexibility in changing vendors, if necessary.
In the cloud native area, we are marked by standards at the compute through the container and orchestration layers because Docker and Kubernetes became universally adopted. However, in the layers above compute, such as with event-driven architecture, Jamstack, and reactive architecture, the number of vendors and competing interests have grown without an emerging standard.
There are some encouraging early efforts:
CNCF Application Efforts: This includes streaming and messaging work with CloudEvents and the wildly popular NATS. It also includes efforts to standardize how objects call one another with gRPC, and many efforts and vendors that are providing application packaging definitions. But arguably, some of these concerns are beyond the compute, and into the application development domain.
The Reactive Foundation (I think it would be better named as the Cloud Native Development Foundation): A foundation for projects and initiatives that improve the developer experience for designing and building applications based on reactive, patterns and projects.
Reactive Manifesto and Reactive Principles: A guiding light with 29K signatories that offers a coherent approach to systems architecture for cloud native systems that are scaling state.
More needs to be done, and the major platform vendors including Red Hat, Microsoft, Oracle, IBM, Google, Amazon, and VMware must step up by supporting industry initiatives that drive common practices for development system while also delivering products and reference implementations. Additionally, well funded startups that have the lion’s share of venture capital and are attempting to create standards through mass adoption (like Kafka + Databricks) must also engage - to create a larger ecosystem that they benefit from and to protect themselves from fragmentation when disgruntled teams seek alternatives.
If these titans fail to step up, the industry will continue to fragment, and developer productivity will slow as developers are forced to sort through a large, and increasingly diverse ecosystem.
Attend the Reactive Summit - November 10th - Who’s Who in Stateful Development
To see the cutting edge of what vendors are designing and tech-forward companies are implementing, the Reactive Summit, hosted by the Linux Foundation, is occurring on November 10th, 2020.
You will see sessions from Microsoft, Netflix, Tesla, Lightbend, Synadia, Ververica, IBM, Red Hat, Facebook, Camunda, ING Bank, Adobe, AxonIQ, Actyx, Digital Ocean, Erlang Solutions, Domino Data Lab, Facebook, UrbanLogiq, Temporal Technologies, VMWare, Google, Titan Class, and Synadia.
Some highlights:
The Reactive Principles: Design Principles for Cloud Native Applications, Jonas Boner, Chairman @ Reactive Foundation
Event-Driven Microservices: The Sense, Nonsense and a Way Forward, Allard Buijze, CTO @ AxonIQ
Reactive Programming with Quarkus — A Reactive Mutiny, Clement Escoffier, Principal Engineer @ Red Hat
The Future of Programming, Francesco Cesarini, Technical Director @ Erlang Solutions, and Veronica Lopez, Software Engineer @ Digital Ocean
Reacting to an Event-Driven World, Grace Jansen, Developer Advocate @ IBM
Reactive Systems: The State of the Art for IoT, Colin Breck, Cloud Platforms @ Tesla
Akka Streams - An Adobe Data-Intensive Story, Bianca Tesila, Software Engineer @ Adobe
Tale of Stateful Stream to Stream Processing, Ajit Koti, Senior Engineer @ Netflix
Reactive Microservices with NATS, Derek Collison, Founder @ Synadia